In this blog post, we will explore the fascinating world of distributed locking mechanisms using Redis. We’ll start with a compelling discussion on why distributed locks are crucial in modern applications. Following that, we’ll introduce Redis and its role in distributed systems. Finally, we’ll outline the purpose of this blog, which is to delve into 10 types of locks that can be implemented with Redis, discussing their pros and cons to help you make informed decisions.
Introduction
In today’s interconnected world, where applications often span across multiple servers and geographical locations, ensuring data consistency and coordination between processes is paramount. Imagine a scenario where multiple instances of your application are trying to update the same resource concurrently. Without proper synchronization, you could end up with race conditions, data corruption, or even system crashes. This is where distributed locks come into play.
Distributed locks are mechanisms that ensure only one process or thread can access a shared resource at a time across multiple nodes in a distributed system. They function by using a central authority to manage lock states, preventing race conditions and ensuring data consistency.
Redis, an in-memory data structure store, is widely known for its versatility and performance. It offers various data structures such as strings, sets, and sorted sets, which can be utilized to implement distributed locks. Redis is often chosen for distributed locking due to its speed, simplicity, and rich feature set.
In this blog post, we will explore the fascinating world of distributed locking mechanisms using Redis. We’ll start with a compelling discussion on why distributed locks are crucial in modern applications. Following that, we’ll introduce Redis and its role in distributed systems. Finally, we’ll outline the purpose of this blog, which is to delve into 10 types of locks that can be implemented with Redis, discussing their pros and cons to help you make informed decisions.
Stay tuned as we dive deep into each lock type, providing code examples, implementation strategies, and a thorough analysis of their advantages and disadvantages. Whether you’re a seasoned engineer or just starting out, this comprehensive guide will equip you with the knowledge to effectively implement distributed locks in your applications.
1. Simple Atomic Lock
The Simple Atomic Lock is one of the most straightforward locking mechanisms you can implement with Redis. It is designed to ensure that a particular resource is accessed by only one client at a time, thereby preventing race conditions in a distributed environment.
What is a Simple Atomic Lock?
A Simple Atomic Lock is a basic form of locking where a client attempts to set a key in Redis only if it does not
already exist. This ensures that only one client can acquire the lock at any given time. The SETNX (Set if Not eXists)
command is typically used to implement this lock. If the key is set successfully, the client has acquired the lock. If
the key already exists, the client knows that another process holds the lock.
Implementation
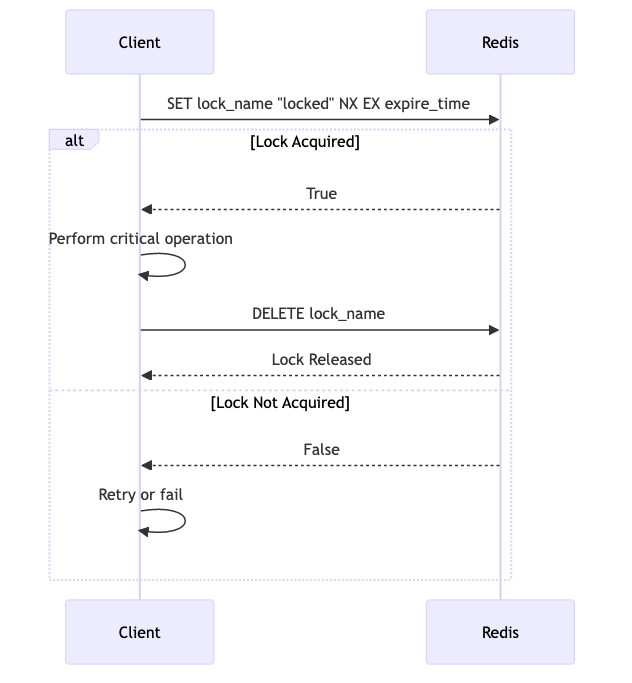
The SETNX command is used to create a Simple Atomic Lock. Below is a Python code example demonstrating how to
implement this:
import redis
import time
## Connect to Redis
client = redis.StrictRedis(host='localhost', port=6379, db=0)
def acquire_lock(lock_name, timeout=10):
"""
Try to acquire a lock with the given name.
:param lock_name: Name of the lock
:param timeout: Timeout in seconds
:return: True if lock is acquired, False otherwise
"""
end_time = time.time() + timeout
while time.time() < end_time:
if client.setnx(lock_name, "locked"):
return True
time.sleep(0.01) # Sleep for 10 milliseconds before trying again
return False
def release_lock(lock_name):
"""
Release the lock with the given name.
:param lock_name: Name of the lock
"""
client.delete(lock_name)
## Example usage
if acquire_lock("my_lock"):
try:
# Perform some critical operation
print("Lock acquired, performing critical operation")
finally:
release_lock("my_lock")
else:
print("Failed to acquire lock")
Pros and Cons
Pros
- Simplicity: The Simple Atomic Lock is easy to understand and implement. The use of the
SETNXcommand makes it straightforward to acquire and release the lock. - Speed: Redis is an in-memory data store, which means that lock acquisition and release are very fast operations.
Cons
- Lack of Expiration Handling: The Simple Atomic Lock does not handle expiration. If a client crashes while holding the lock, the lock will remain indefinitely, potentially causing a deadlock.
- Race Conditions During Lock Release: There is a risk of race conditions when releasing the lock. If a client releases the lock and another client acquires it immediately, there might be inconsistencies.
- No Distributed Coordination: In a distributed setup, this lock does not handle network partitions or Redis node failures, which can lead to reliability issues.
Enhancing the Simple Atomic Lock
To address some of the cons, you can enhance the Simple Atomic Lock by adding expiration handling and using Lua scripts
for atomic operations. For example, you can use the SET command with the NX and EX options to set a key only if it
does not exist and also set an expiration time:
def acquire_lock_with_expiration(lock_name, timeout=10, expire_time=60):
"""
Try to acquire a lock with the given name and set an expiration time.
:param lock_name: Name of the lock
:param timeout: Timeout in seconds
:param expire_time: Expiration time in seconds
:return: True if lock is acquired, False otherwise
"""
end_time = time.time() + timeout
while time.time() < end_time:
if client.set(lock_name, "locked", nx=True, ex=expire_time):
return True
time.sleep(0.01) # Sleep for 10 milliseconds before trying again
return False
This enhancement ensures that the lock will automatically expire after a specified time, reducing the risk of deadlocks.
2. Expiring Lock
Expiring Locks add a layer of sophistication by incorporating automatic expiration. This type of lock ensures that if a process fails to release the lock, it will eventually be released automatically after a specified time period. This helps in preventing deadlocks and stale locks that could otherwise hinder the system’s performance.
Concept of an Expiring Lock
An Expiring Lock is essentially a lock that has a built-in timeout. When a process acquires the lock, it sets an expiration time. If the process completes its task and releases the lock before the expiration time, everything works as expected. However, if the process crashes or takes too long, the lock will automatically be released after the expiration time, making it available for other processes.
Implementation
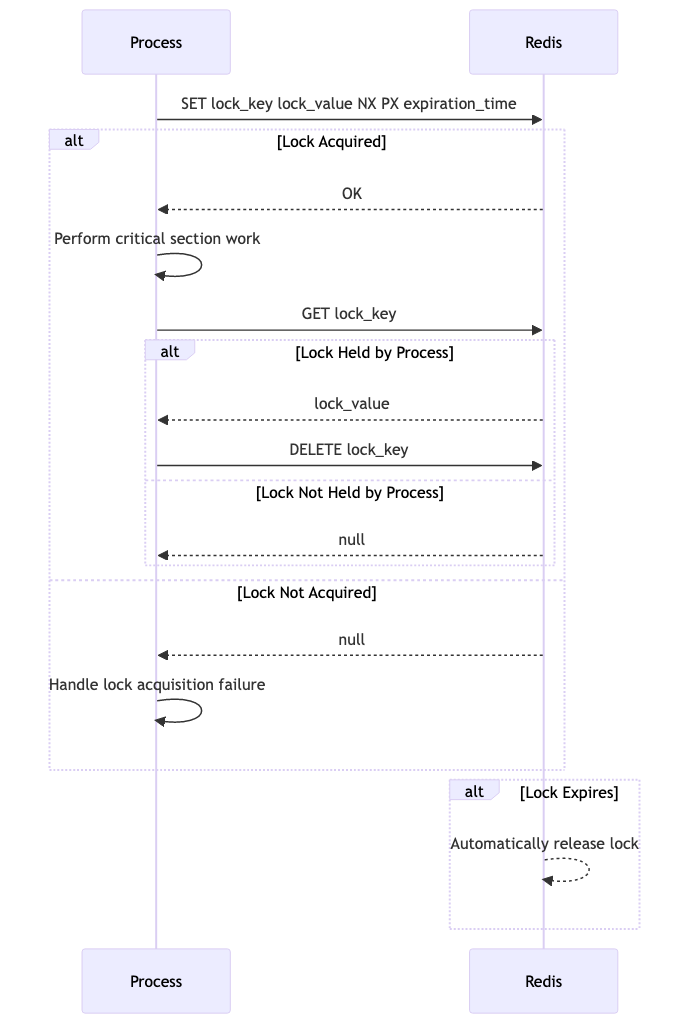
To implement an Expiring Lock in Redis, you can use the SET command with the NX (set if not exists) and PX (set
expiration in milliseconds) options. Here’s a simple example in Python:
import redis
import time
## Connect to Redis
r = redis.Redis()
lock_key = "expiring_lock"
lock_value = "unique_process_id"
expiration_time = 5000 # milliseconds
## Try to acquire the lock with an expiration time
if r.set(lock_key, lock_value, nx=True, px=expiration_time):
try:
# Perform critical section work
print("Lock acquired, performing critical section work")
time.sleep(3) # Simulate work by sleeping for 3 seconds
finally:
# Release the lock only if it's still held by this process
if r.get(lock_key) == lock_value:
r.delete(lock_key)
else:
print("Failed to acquire lock")
In this example, the lock is set with a key (lock_key), a unique value (lock_value), and an expiration
time (expiration_time). The SET command with NX ensures that the lock is only set if it does not already exist,
and PX sets the expiration time in milliseconds.
Pros and Cons
Pros
- Automatic Cleanup: The primary advantage of an Expiring Lock is that it automatically cleans up stale locks, preventing deadlocks and ensuring that resources are not indefinitely locked.
- Simplicity: It simplifies the lock management by not requiring explicit lock release in case of failures or crashes.
- Flexibility: The expiration time can be adjusted based on the expected duration of the critical section, providing flexibility in lock management.
Cons
- Complexity in Handling Expiration: Managing the expiration time can be complex, especially if the critical section’s duration is unpredictable. If the expiration time is too short, the lock might expire before the task is completed, leading to potential inconsistencies.
- Renewal Mechanism: In cases where the task takes longer than expected, a mechanism to renew the lock before it expires is needed. Implementing this renewal mechanism can add complexity to the system.
- Clock Drift: In distributed systems, clock drift between different nodes can affect the reliability of lock expiration, potentially leading to premature lock releases.
By using Expiring Locks, you can mitigate the risk of deadlocks and ensure that your system remains responsive even in the face of unexpected failures. However, it’s crucial to carefully manage the expiration time and consider implementing a renewal mechanism for long-running tasks.
3. Redlock Algorithm
The Redlock Algorithm is designed for high reliability in distributed systems. It addresses the complexities and challenges of distributed locking, ensuring that locks are acquired and released reliably, even in the presence of network partitions and node failures. Developed by Salvatore Sanfilippo, the creator of Redis, the Redlock Algorithm aims to provide a robust solution for distributed locking.
Purpose of the Redlock Algorithm
The primary goal of the Redlock Algorithm is to ensure that no two clients can hold the same lock simultaneously, thereby preventing race conditions and ensuring data consistency. It achieves this by leveraging multiple Redis instances to create a consensus on the lock state.
Implementation
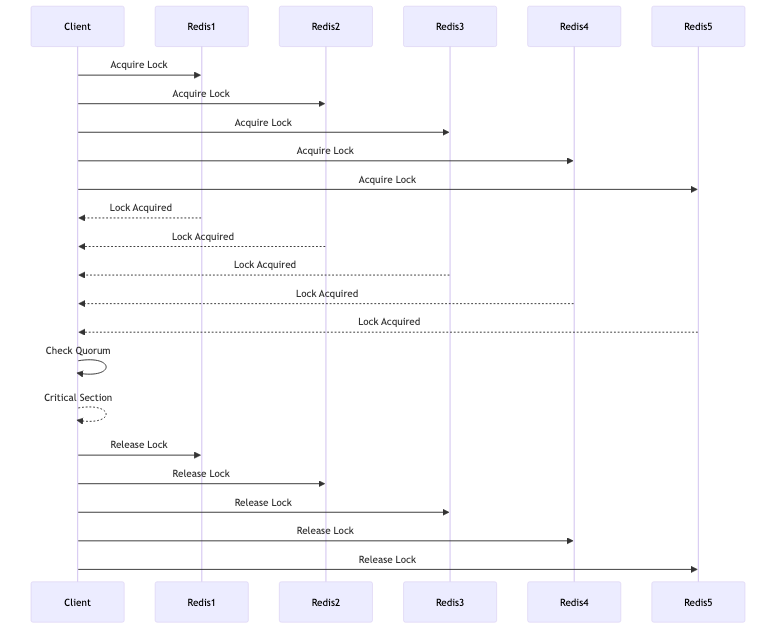
The Redlock Algorithm involves the following steps:
- Acquire Locks on N/2+1 Instances: The client attempts to acquire the lock on a majority of Redis instances ( N/2+1) using a unique identifier and a TTL (Time To Live).
- Check the Quorum: If the client successfully acquires the lock on the majority of instances, it considers the lock to be acquired.
- Set Expiration Time: The lock is set with an expiration time to ensure it is not held indefinitely.
- Release Locks: Upon completion of the critical section, the client releases the lock on all instances.
Below is a pseudocode example to illustrate the Redlock Algorithm:
import time
import uuid
import redis
def acquire_lock(redis_clients, lock_key, ttl):
identifier = str(uuid.uuid4())
quorum = len(redis_clients) // 2 + 1
acquired_locks = 0
for client in redis_clients:
if client.set(lock_key, identifier, nx=True, px=ttl):
acquired_locks += 1
if acquired_locks >= quorum:
return identifier
else:
for client in redis_clients:
client.delete(lock_key)
return False
def release_lock(redis_clients, lock_key, identifier):
for client in redis_clients:
if client.get(lock_key) == identifier:
client.delete(lock_key)
## Example usage
redis_clients = [redis.StrictRedis(host='localhost', port=6379) for _ in range(5)]
lock_key = "distributed_lock"
ttl = 10000 # 10 seconds
lock_identifier = acquire_lock(redis_clients, lock_key, ttl)
if lock_identifier:
try:
# Critical section
print("Lock acquired, performing critical operations.")
finally:
release_lock(redis_clients, lock_key, lock_identifier)
print("Lock released.")
else:
print("Failed to acquire lock.")
Pros and Cons
Pros:
- Increased Fault Tolerance: By requiring a quorum of instances to acquire the lock, the Redlock Algorithm ensures higher fault tolerance. Even if some instances fail, the lock can still be acquired and released reliably.
- Safety Guarantees: The algorithm ensures that no two clients can hold the same lock simultaneously, preventing race conditions.
- Liveness Guarantees: Clients will eventually acquire the lock if they continue to retry, even in the presence of failures.
Cons:
- Complexity: Implementing the Redlock Algorithm is more complex compared to simpler locking mechanisms. It requires careful handling of multiple Redis instances and ensuring time synchronization.
- Performance Overhead: Acquiring and releasing locks on multiple instances can introduce performance overhead, especially in high-throughput systems.
- Clock Drift: The algorithm assumes that the clocks of Redis instances are reasonably synchronized. Clock drift can lead to inconsistencies if not properly managed.
By understanding the Redlock Algorithm and its trade-offs, you can make informed decisions about when and how to use it in your distributed systems.
4. Semaphore
Semaphores are a powerful synchronization mechanism used to control access to a shared resource by multiple clients. In a distributed system, semaphores can help manage resource contention and ensure that resources are used efficiently without conflicts.
What is a Semaphore?
A semaphore is essentially a counter that controls access to a resource. It can be incremented or decremented atomically to signal the availability or usage of a resource. There are two main types of semaphores:
- Binary Semaphore: This type of semaphore can only take two values, 0 and 1, and is often used as a simple lock.
- Counting Semaphore: This type can hold any non-negative integer value and is used to manage a pool of resources.
In the context of Redis, we typically use counting semaphores to manage access to a limited number of resources.
Typical Use Cases
Semaphores are commonly used in scenarios where you need to:
- Limit Concurrent Access: Control the number of clients that can access a particular resource simultaneously.
- Manage Resource Pools: Ensure that a limited number of resources (e.g., database connections, threads) are used efficiently.
- Coordinate Tasks: Synchronize tasks in a distributed system to avoid conflicts and ensure proper sequencing.
Implementation Using INCR
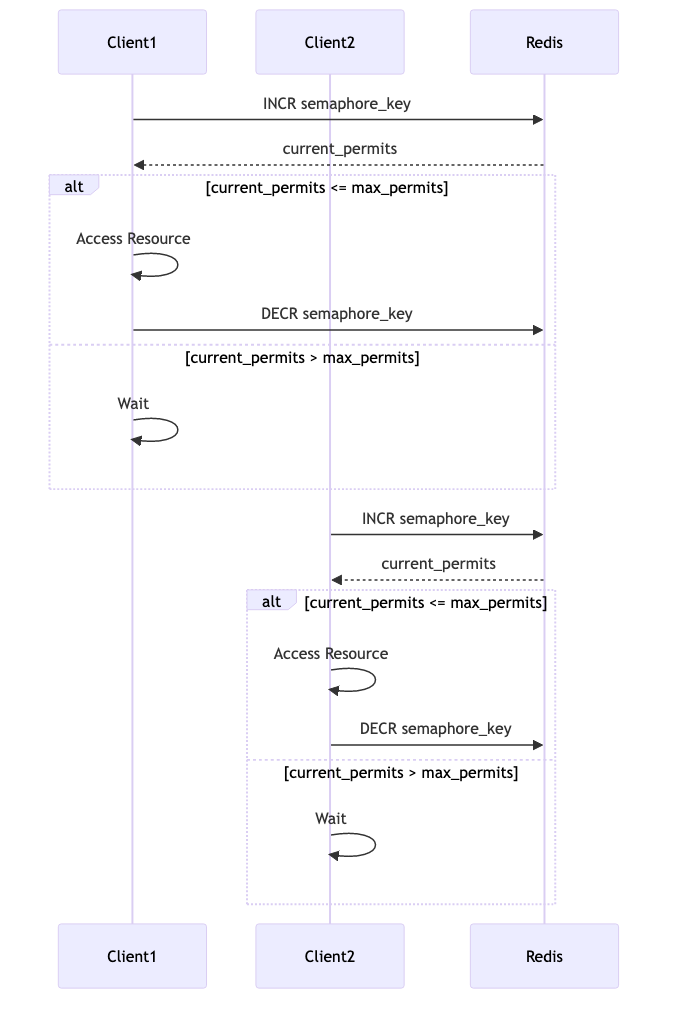
Let’s look at how to implement a counting semaphore in Redis using the INCR and DECR commands. The idea is to use a
Redis key as the semaphore counter, which is incremented when a resource is acquired and decremented when it is
released.
Here is a Python example:
import redis
class RedisSemaphore:
def __init__(self, redis_client, semaphore_key, max_permits):
self.redis_client = redis_client
self.semaphore_key = semaphore_key
self.max_permits = max_permits
def acquire(self):
while True:
current_permits = int(self.redis_client.get(self.semaphore_key) or 0)
if current_permits < self.max_permits:
if self.redis_client.incr(self.semaphore_key) <= self.max_permits:
return True
else:
self.redis_client.decr(self.semaphore_key)
else:
# Sleep or wait for a while before retrying
time.sleep(0.1)
def release(self):
self.redis_client.decr(self.semaphore_key)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
semaphore_key = "resource_semaphore"
max_permits = 5
semaphore = RedisSemaphore(redis_client, semaphore_key, max_permits)
if semaphore.acquire():
try:
# Critical section
print("Resource acquired, performing operations.")
finally:
semaphore.release()
print("Resource released.")
else:
print("Failed to acquire resource.")
Pros and Cons
Pros:
- Concurrency Control: Semaphores allow you to manage access to resources by multiple clients, ensuring that no more than a specified number of clients can access the resource simultaneously.
- Flexibility: Counting semaphores can be used to manage a pool of resources, making them versatile for various use cases.
- Simplicity: The basic implementation of a semaphore using Redis commands is straightforward and easy to understand.
Cons:
- Race Conditions: Managing semaphore counts can be challenging, especially in a highly concurrent environment. Care must be taken to ensure atomic operations to prevent race conditions.
- Deadlocks: Improper handling of semaphore acquisition and release can lead to deadlocks, where clients are indefinitely waiting for a resource.
- Resource Starvation: Without proper management, some clients may be starved of resources if others continuously acquire the semaphore.
By understanding the use cases and implementation details of semaphores, you can effectively manage resource access in your distributed systems.
5. Fair Lock
In distributed systems, fairness is often a critical requirement to ensure that all clients get an equitable opportunity to acquire a lock. This is where Fair Locks come into play. Unlike regular locks that might favor certain clients, Fair Locks guarantee that all clients have a fair chance to acquire the lock, preventing issues like starvation and priority inversion.
Concept of a Fair Lock
A Fair Lock ensures that requests to acquire the lock are handled in the order they are received. This is typically achieved by maintaining a queue of clients waiting to acquire the lock. When the lock is released, the next client in the queue is granted access. This mechanism prevents any single client from monopolizing the lock and ensures that all clients are treated equally.
Key Characteristics of Fair Locks
- Starvation Prevention: Ensures that no client is perpetually denied access to the lock.
- Orderly Access: Clients acquire the lock in the order they requested it, maintaining a first-come, first-served policy.
- Avoidance of Priority Inversion: Prevents lower-priority tasks from blocking higher-priority tasks indefinitely.
Implementation Using a Queue
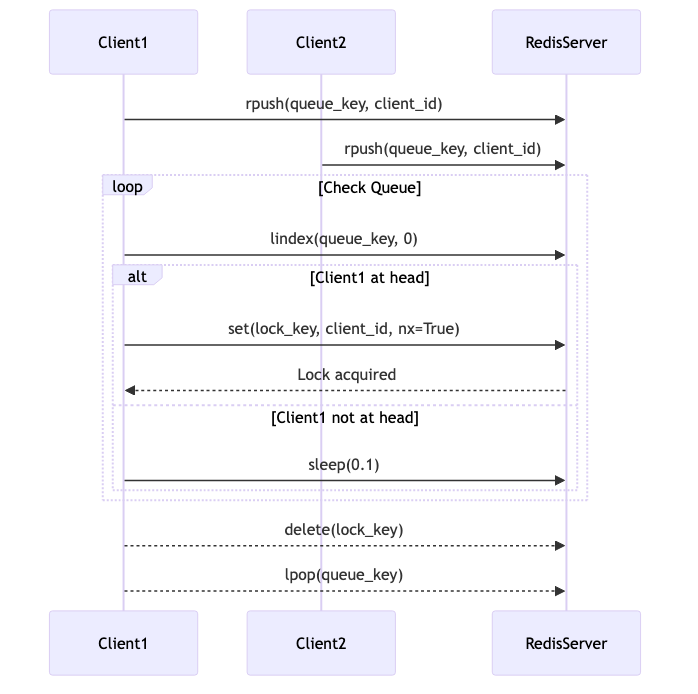 Let’s implement a Fair Lock using Redis and a queue. We’ll use Redis lists to manage the queue of clients waiting to
acquire the lock. The idea is to push client identifiers to the list when they request the lock and pop them when they
acquire it.
Let’s implement a Fair Lock using Redis and a queue. We’ll use Redis lists to manage the queue of clients waiting to
acquire the lock. The idea is to push client identifiers to the list when they request the lock and pop them when they
acquire it.
Here’s a Python example:
import redis
import time
import uuid
class RedisFairLock:
def __init__(self, redis_client, lock_key):
self.redis_client = redis_client
self.lock_key = lock_key
self.queue_key = f"{lock_key}_queue"
self.client_id = str(uuid.uuid4())
def acquire(self):
self.redis_client.rpush(self.queue_key, self.client_id)
while True:
queue_head = self.redis_client.lindex(self.queue_key, 0)
if queue_head == self.client_id:
if self.redis_client.set(self.lock_key, self.client_id, nx=True):
return True
time.sleep(0.1)
def release(self):
if self.redis_client.get(self.lock_key) == self.client_id:
self.redis_client.delete(self.lock_key)
self.redis_client.lpop(self.queue_key)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_key = "fair_lock"
fair_lock = RedisFairLock(redis_client, lock_key)
if fair_lock.acquire():
try:
# Critical section
print("Lock acquired fairly, performing operations.")
finally:
fair_lock.release()
print("Lock released.")
else:
print("Failed to acquire lock.")
In this implementation:
- Each client is assigned a unique identifier (
client_id). - Clients push their identifier to the queue when they request the lock.
- Clients continuously check if they are at the head of the queue and attempt to acquire the lock.
- Upon acquiring the lock, the client removes itself from the queue when releasing the lock.
Pros and Cons
Pros:
- Fairness: Ensures that all clients get an equal chance to acquire the lock, preventing starvation.
- Orderly Access: Maintains the order of lock requests, ensuring that clients are served in a first-come, first-served manner.
- Avoids Priority Inversion: Prevents lower-priority tasks from indefinitely blocking higher-priority tasks.
Cons:
- Increased Complexity: Managing a queue and ensuring fair access adds complexity to the lock implementation.
- Performance Trade-offs: The overhead of maintaining and checking the queue can reduce throughput compared to non-fair locks.
- Timeout Handling: Clients might need to implement timeouts to avoid waiting indefinitely, which adds additional logic.
By incorporating Fair Locks into your distributed systems, you can ensure that all clients are treated equitably, enhancing the overall robustness and reliability of your application.
6. Read-Write Lock
Description
Read-Write Locks are a synchronization primitive that allows multiple readers or a single writer to access a shared resource. This type of lock is particularly beneficial in scenarios where read operations are frequent and write operations are less common. By allowing multiple readers to access the resource concurrently, Read-Write Locks can significantly improve the performance of read-heavy workloads.
Implementation Using Counters
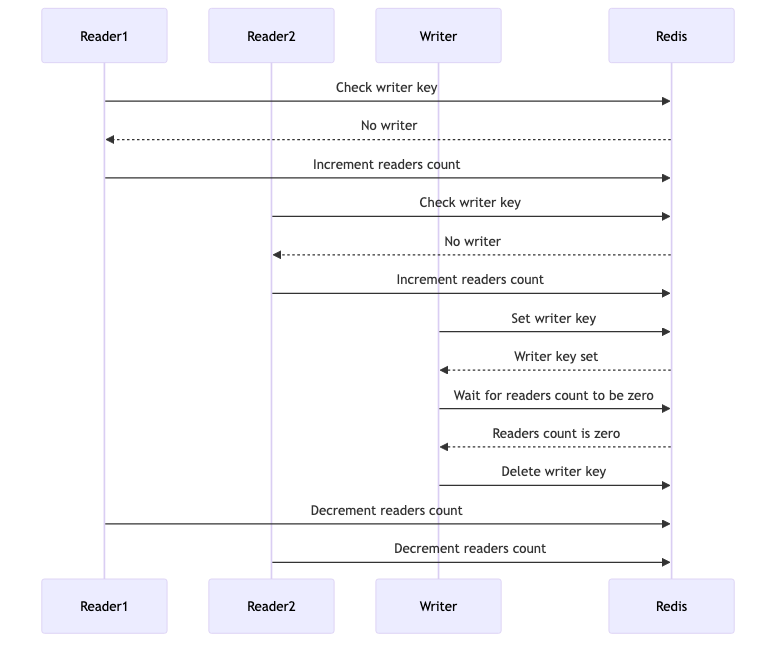
Let’s implement a Read-Write Lock using Redis and counters. We’ll use Redis keys to manage the count of active readers and a separate key to manage the writer lock state.
Here’s a Python example:
import redis
import time
class RedisReadWriteLock:
def __init__(self, redis_client, lock_key):
self.redis_client = redis_client
self.readers_key = f"{lock_key}_readers"
self.writer_key = f"{lock_key}_writer"
def acquire_read(self):
while True:
if not self.redis_client.exists(self.writer_key):
self.redis_client.incr(self.readers_key)
if not self.redis_client.exists(self.writer_key):
return True
self.redis_client.decr(self.readers_key)
time.sleep(0.1)
def release_read(self):
self.redis_client.decr(self.readers_key)
def acquire_write(self):
while True:
if self.redis_client.set(self.writer_key, "1", nx=True):
while self.redis_client.get(self.readers_key) != b"0":
time.sleep(0.1)
return True
time.sleep(0.1)
def release_write(self):
self.redis_client.delete(self.writer_key)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_key = "read_write_lock"
rw_lock = RedisReadWriteLock(redis_client, lock_key)
## Acquiring a read lock
if rw_lock.acquire_read():
try:
# Critical section for reading
print("Read lock acquired, performing read operations.")
finally:
rw_lock.release_read()
print("Read lock released.")
## Acquiring a write lock
if rw_lock.acquire_write():
try:
# Critical section for writing
print("Write lock acquired, performing write operations.")
finally:
rw_lock.release_write()
print("Write lock released.")
In this implementation:
- Readers increment a counter when they acquire the read lock and decrement it when they release the read lock.
- Writers set a key when they acquire the write lock and wait for the readers’ counter to reach zero before proceeding.
- The writer key ensures that no new readers can acquire the lock while a writer is waiting or has acquired the lock.
Pros and Cons
Pros:
- Improved Concurrency: Allows multiple readers to access the resource concurrently, improving performance for read-heavy workloads.
- Efficient Resource Utilization: Reduces the time the resource is locked compared to a standard mutex, as multiple readers can access it simultaneously.
- Scalability: Suitable for applications with high read-to-write ratios, enhancing scalability.
Cons:
- Increased Complexity: Managing separate states for readers and writers adds complexity to the implementation.
- Potential Starvation: Writers may experience starvation if there is a constant stream of readers. Implementing fairness mechanisms can mitigate this issue.
- Performance Overhead: The overhead of managing counters and checking states can impact performance, especially in high-contention scenarios.
By incorporating Read-Write Locks into your distributed systems, you can achieve higher concurrency and better performance for read-heavy workloads, while also balancing the complexities and potential trade-offs involved.
7. Reentrant Lock
Reentrant Locks are a specialized type of lock that allows the same client to acquire the lock multiple times without causing a deadlock. This feature is particularly useful in scenarios where a function might need to re-acquire the lock it already holds, such as in recursive functions or complex workflows where multiple lock acquisitions are necessary.
Description
A Reentrant Lock ensures that the same thread or client can acquire the lock as many times as needed, as long as it releases the lock the same number of times. This type of lock is crucial in avoiding deadlocks in recursive calls or nested lock acquisitions, where the same client needs to lock and unlock a resource multiple times.
Implementation
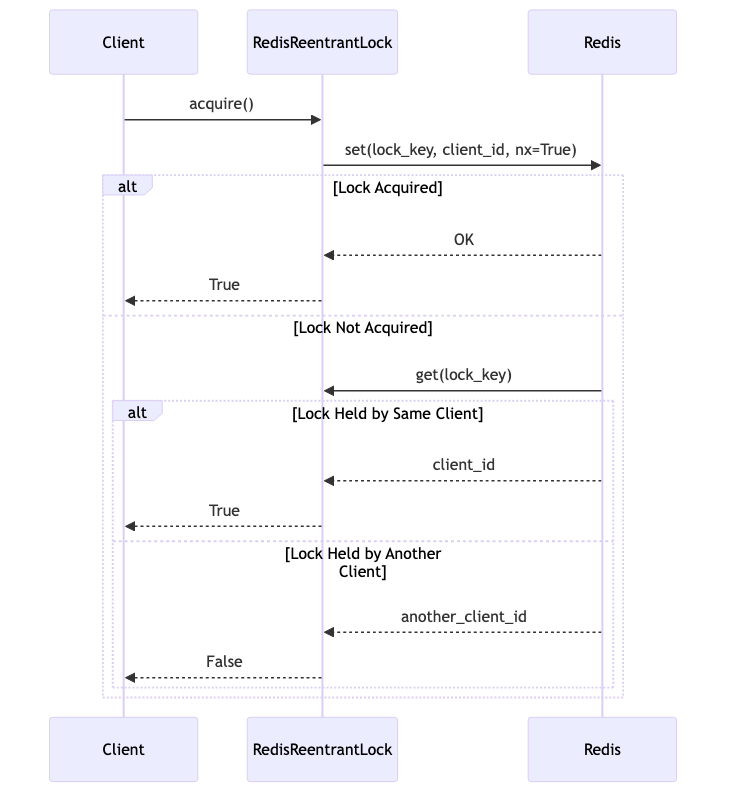 We can implement a Reentrant Lock in Redis using hash counters to manage the lock acquisition count for each client.
Here is a Python implementation using the
We can implement a Reentrant Lock in Redis using hash counters to manage the lock acquisition count for each client.
Here is a Python implementation using the redis-py library:
import redis
import threading
class RedisReentrantLock:
def __init__(self, redis_client, lock_key):
self.redis_client = redis_client
self.lock_key = lock_key
self.thread_local = threading.local()
def _get_lock_count(self):
return getattr(self.thread_local, 'lock_count', 0)
def _set_lock_count(self, count):
self.thread_local.lock_count = count
def acquire(self):
client_id = threading.get_ident()
lock_count = self._get_lock_count()
if lock_count == 0:
if self.redis_client.set(self.lock_key, client_id, nx=True):
self._set_lock_count(1)
return True
elif self.redis_client.get(self.lock_key) == str(client_id).encode():
self._set_lock_count(lock_count + 1)
return True
else:
if self.redis_client.get(self.lock_key) == str(client_id).encode():
self._set_lock_count(lock_count + 1)
return True
return False
def release(self):
client_id = threading.get_ident()
lock_count = self._get_lock_count()
if lock_count == 0:
raise RuntimeError("Cannot release an unacquired lock")
if self.redis_client.get(self.lock_key) == str(client_id).encode():
if lock_count == 1:
self.redis_client.delete(self.lock_key)
self._set_lock_count(0)
else:
self._set_lock_count(lock_count - 1)
else:
raise RuntimeError("Lock held by another client")
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_key = "reentrant_lock"
reentrant_lock = RedisReentrantLock(redis_client, lock_key)
## Acquiring the lock
if reentrant_lock.acquire():
try:
# Critical section
print("Lock acquired, performing operations.")
# Re-acquiring the lock
if reentrant_lock.acquire():
try:
print("Lock re-acquired, performing nested operations.")
finally:
reentrant_lock.release()
print("Nested lock released.")
finally:
reentrant_lock.release()
print("Lock released.")
In this implementation:
- The
acquiremethod checks if the current client already holds the lock by comparing the stored client ID. If the lock is not held, it attempts to set the lock key in Redis. - The
releasemethod decrements the lock count and deletes the lock key if the count reaches zero. - The
thread_localstorage is used to keep track of the lock count for each client.
Pros and Cons
Pros:
- Ease of Use in Recursive Functions: Allows the same client to acquire the lock multiple times, which is particularly useful in recursive functions or complex workflows.
- Thread Safety: Ensures that the same client can safely re-acquire the lock without causing a deadlock.
- Flexibility: Suitable for scenarios where nested lock acquisitions are necessary.
Cons:
- Additional Overhead: Managing lock counts introduces additional overhead, which can impact performance, especially in high-contention scenarios.
- Complexity: The implementation is more complex compared to simple locks, as it requires tracking the number of times the lock has been acquired by each client.
- Potential for Misuse: Incorrect usage, such as failing to release the lock properly, can lead to deadlocks or resource leaks.
By incorporating Reentrant Locks into your distributed systems, you can manage complex workflows and recursive functions more effectively, while balancing the additional overhead and complexity involved.
8. Multi-key Lock
When working with distributed systems, there are scenarios where you need to perform atomic operations on multiple keys to maintain data consistency. This is where Multi-key Locks come into play. They ensure that a set of keys is locked atomically, preventing other clients from modifying any key in the set while the lock is held.
The Need for Atomic Locking of Multiple Keys
In a distributed environment, operations often span multiple keys. For example, consider a financial transaction where funds are transferred from one account to another. To ensure consistency, you need to lock both accounts simultaneously. Without atomic locking, there’s a risk of race conditions, leading to data inconsistencies.
Implementation Using Lua Scripting
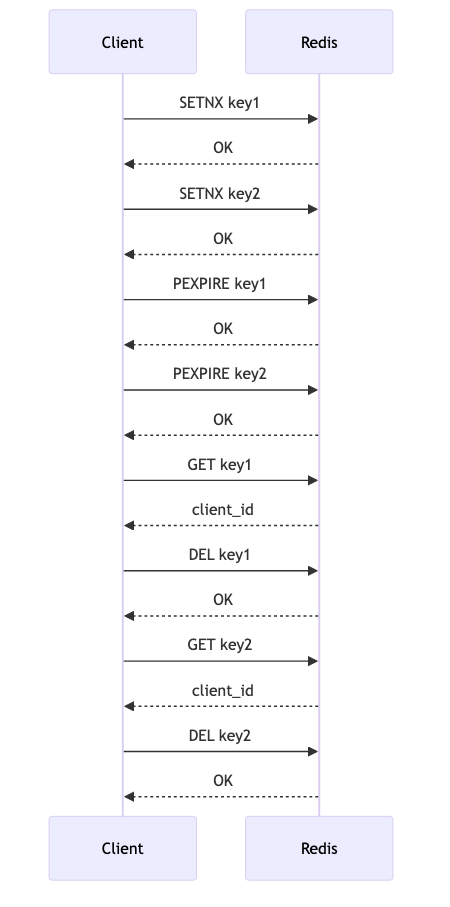
Redis supports Lua scripting, which allows you to execute a sequence of commands atomically. Below is an example of implementing a Multi-key Lock using Lua scripting:
import redis
## Lua script to acquire a multi-key lock
acquire_lock_script = """
local keys = KEYS
local client_id = ARGV[1]
local ttl = tonumber(ARGV[2])
for i = 1, #keys do
if redis.call('SETNX', keys[i], client_id) == 0 then
for j = 1, i-1 do
redis.call('DEL', keys[j])
end
return 0
end
redis.call('PEXPIRE', keys[i], ttl)
end
return 1
"""
## Lua script to release a multi-key lock
release_lock_script = """
local keys = KEYS
local client_id = ARGV[1]
for i = 1, #keys do
if redis.call('GET', keys[i]) == client_id then
redis.call('DEL', keys[i])
end
end
return 1
"""
class RedisMultiKeyLock:
def __init__(self, redis_client, lock_keys, ttl=10000):
self.redis_client = redis_client
self.lock_keys = lock_keys
self.client_id = str(threading.get_ident())
self.ttl = ttl
def acquire(self):
return self.redis_client.eval(acquire_lock_script, len(self.lock_keys), *self.lock_keys, self.client_id,
self.ttl)
def release(self):
return self.redis_client.eval(release_lock_script, len(self.lock_keys), *self.lock_keys, self.client_id)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_keys = ["account:1", "account:2"]
multi_key_lock = RedisMultiKeyLock(redis_client, lock_keys)
## Acquiring the lock
if multi_key_lock.acquire():
try:
# Critical section
print("Lock acquired, performing operations on multiple keys.")
finally:
multi_key_lock.release()
print("Lock released.")
Pros and Cons
Pros:
- Atomicity Across Multiple Keys: Ensures that a set of keys is locked atomically, which is crucial for maintaining data consistency in distributed systems.
- Flexibility: Can be used for various complex operations that span multiple keys, such as financial transactions, inventory management, etc.
- Error Handling: Lua scripting allows for sophisticated error handling and rollback mechanisms, ensuring that partial changes are reverted if the lock cannot be acquired.
Cons:
- Increased Complexity: Implementing multi-key locks is more complex compared to single-key locks. It requires careful handling of lock acquisition and release to prevent deadlocks and ensure consistency.
- Potential Performance Issues: Locking multiple keys can lead to increased contention and performance overhead, especially in high-concurrency scenarios.
- Resource Management: Holding multiple locks simultaneously can consume more resources, necessitating efficient management and cleanup mechanisms.
By leveraging Multi-key Locks with Redis, you can achieve atomic operations across multiple keys, ensuring data consistency and reliability in distributed systems. However, it’s essential to balance the added complexity and potential performance impact with the benefits of atomicity and flexibility.
9. Zookeeper-style Lock
Zookeeper-style locks are a robust and fault-tolerant distributed locking mechanism inspired by Apache ZooKeeper. They are designed to handle scenarios where multiple clients need to coordinate access to shared resources in a distributed environment. Unlike simple locks, Zookeeper-style locks ensure that locks are acquired in a specific order, making them suitable for complex coordination tasks.
Concept
The fundamental concept behind Zookeeper-style locks involves the use of unique identifiers and expiration times. Each client attempting to acquire a lock creates a unique node in a ZooKeeper ensemble. These nodes are ephemeral, meaning they automatically expire if the client session ends. This ensures that locks are automatically released if a client crashes or loses connectivity.
Implementation
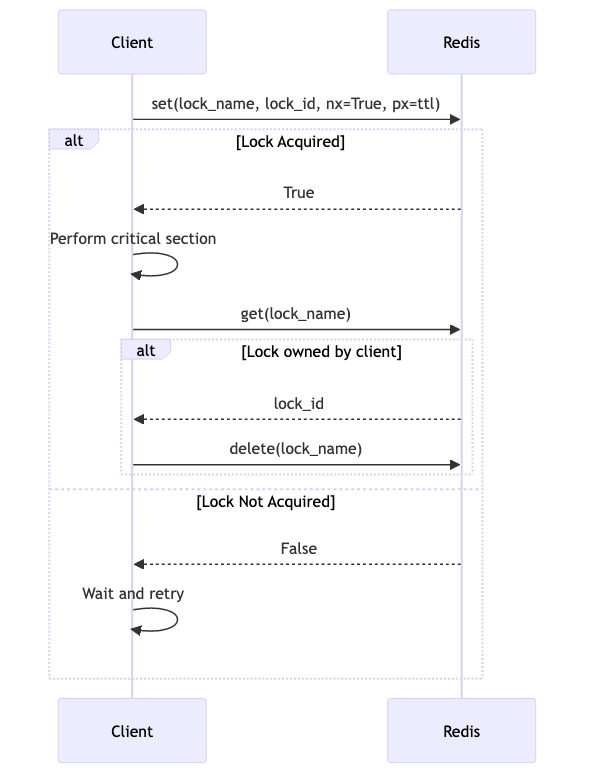
Let’s delve into the implementation of Zookeeper-style locks using unique identifiers and expiration times. Below is a code example demonstrating how to achieve this using Redis.
import redis
import uuid
import time
class ZookeeperStyleLock:
def __init__(self, redis_client, lock_name, ttl=10000):
self.redis_client = redis_client
self.lock_name = lock_name
self.ttl = ttl
self.lock_id = str(uuid.uuid4())
def acquire(self):
while True:
# Try to create a unique node with an expiration time
if self.redis_client.set(self.lock_name, self.lock_id, nx=True, px=self.ttl):
return True
# Wait for a short period before retrying
time.sleep(0.1)
def release(self):
# Ensure that only the client that acquired the lock can release it
if self.redis_client.get(self.lock_name) == self.lock_id:
self.redis_client.delete(self.lock_name)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_name = "zookeeper-style-lock"
zookeeper_lock = ZookeeperStyleLock(redis_client, lock_name)
## Acquiring the lock
if zookeeper_lock.acquire():
try:
# Critical section
print("Lock acquired, performing operations.")
finally:
zookeeper_lock.release()
print("Lock released.")
Pros and Cons
Pros:
- Robustness: Zookeeper-style locks provide a robust mechanism for distributed locking, ensuring that locks are automatically released if a client crashes or loses connectivity.
- Fault Tolerance: The use of ephemeral nodes tied to client sessions ensures that locks are resilient to failures, making them suitable for high-availability systems.
- Orderly Lock Acquisition: Sequential node creation ensures that locks are acquired in a specific order, preventing race conditions and ensuring fair access to shared resources.
Cons:
- Increased Complexity: Implementing Zookeeper-style locks involves more complexity compared to simple locks. It requires careful handling of unique identifiers, expiration times, and session management.
- Potential Performance Overhead: The need to continuously check and renew locks can introduce performance overhead, especially in high-concurrency scenarios.
- Resource Management: Managing ephemeral nodes and ensuring their timely cleanup can consume additional resources, necessitating efficient management mechanisms.
By leveraging Zookeeper-style locks, you can achieve robust and fault-tolerant distributed locking, ensuring orderly access to shared resources in a distributed environment. However, it’s essential to balance the added complexity and potential performance impact with the benefits of robustness and fault tolerance.
10. Lease Lock
Lease Locks are a powerful mechanism in distributed systems, allowing for the acquisition and renewal of locks with a specified lease period. This type of lock is particularly useful when you need to ensure that a lock is held only for a certain amount of time, after which it can be automatically released if not renewed. This ensures that resources are not indefinitely locked due to client failures or network issues.
Concept of a Lease Lock
A Lease Lock is designed to be held for a specific duration, known as the lease period. If the lock holder needs to continue holding the lock, it must renew the lease before it expires. This mechanism provides flexibility in lock duration and ensures that locks are automatically released if the holder fails to renew them in time.
Implementation
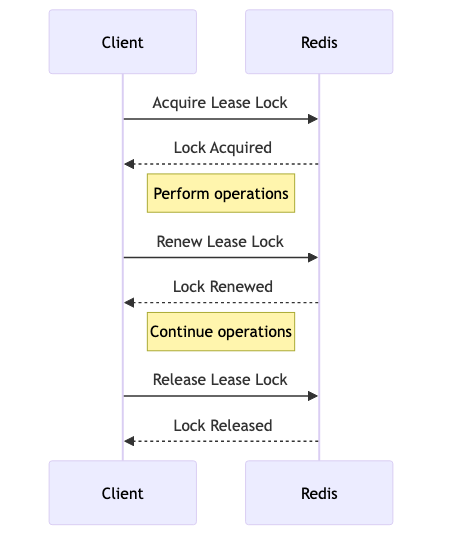
Let’s explore the implementation of a Lease Lock using Redis. Below is a code example demonstrating how to acquire and renew a lease lock.
import redis
import uuid
import time
class LeaseLock:
def __init__(self, redis_client, lock_name, lease_time=10):
self.redis_client = redis_client
self.lock_name = lock_name
self.lease_time = lease_time
self.lock_id = str(uuid.uuid4())
def acquire(self):
return self.redis_client.set(self.lock_name, self.lock_id, nx=True, ex=self.lease_time)
def renew(self):
# Ensure that only the client that acquired the lock can renew it
if self.redis_client.get(self.lock_name) == self.lock_id:
return self.redis_client.expire(self.lock_name, self.lease_time)
return False
def release(self):
# Ensure that only the client that acquired the lock can release it
if self.redis_client.get(self.lock_name) == self.lock_id:
self.redis_client.delete(self.lock_name)
## Example usage
redis_client = redis.StrictRedis(host='localhost', port=6379)
lock_name = "lease-lock"
lease_lock = LeaseLock(redis_client, lock_name, lease_time=10)
## Acquiring the lock
if lease_lock.acquire():
try:
# Critical section
print("Lock acquired, performing operations.")
# Simulate some operations
time.sleep(5)
# Renew the lock
if lease_lock.renew():
print("Lock renewed.")
else:
print("Failed to renew the lock.")
finally:
lease_lock.release()
print("Lock released.")
else:
print("Failed to acquire the lock.")
Pros and Cons
Pros:
- Flexibility in Lock Duration: Lease Locks allow for dynamic control over the lock duration, making them suitable for scenarios where the lock holding time is uncertain.
- Automatic Release: Locks are automatically released if not renewed, preventing indefinite lock holding due to client failures.
- Improved Resource Management: The automatic expiration of locks ensures efficient resource utilization and prevents deadlocks.
Cons:
- Complexity in Renewal Management: Managing lease renewals can be complex, especially in high-concurrency environments where multiple clients may attempt to renew the lock simultaneously.
- Potential for Race Conditions: If a client fails to renew the lock in time, other clients may acquire the lock, potentially leading to race conditions.
- Performance Overhead: The need to continuously renew locks can introduce performance overhead, particularly in systems with high lock contention.
Lease Locks provide a robust mechanism for distributed locking with flexible lease periods, ensuring efficient resource management and preventing indefinite lock holding. However, careful handling of lease renewals and concurrency is essential to avoid potential pitfalls.
Summary Table
For quick reference, we’ll provide a summary table that lists the pros and cons of each lock type discussed. This table will help you compare the different locking mechanisms at a glance and make informed decisions based on your specific use case requirements.
| Lock Type | Pros | Cons |
|---|---|---|
| Simple Atomic Lock | - Easy to implement - Low overhead |
- No expiration mechanism - Risk of deadlocks |
| Expiring Lock | - Automatic expiration - Prevents indefinite lock holding |
- Potential for race conditions - Requires careful management of expiration times |
| Redlock Algorithm | - High reliability - Suitable for distributed systems |
- Complex implementation - Performance overhead due to multiple Redis instances |
| Semaphore | - Allows multiple clients - Suitable for rate limiting |
- Requires careful management - Can be complex to implement |
| Fair Lock | - Ensures fair access - Prevents starvation |
- Higher complexity - Potential performance overhead |
| Read-Write Lock | - Optimizes read-heavy workloads - Allows multiple readers |
- Complex implementation - Potential for write starvation |
| Reentrant Lock | - Allows re-entrance by the same client - Suitable for recursive operations |
- Higher complexity - Requires careful tracking of lock ownership |
| Multi-key Lock | - Atomic locking of multiple keys - Suitable for complex transactions |
- Requires Lua scripting - Higher complexity |
| Zookeeper-style Lock | - High reliability - Suitable for hierarchical locking |
- Complex implementation - Potential performance overhead |
| Lease Lock | - Flexible lock duration - Automatic release |
- Complexity in renewal management - Potential for race conditions - Performance overhead |
This table should serve as a handy guide for selecting the appropriate lock type for your distributed system needs. Each lock type has its unique strengths and weaknesses, making it crucial to understand the specific requirements of your application before making a choice.



